
It’s 2025. Businesses don’t just run on data, they improve on data. They deliver on data. They earn on data. They exist on data. But to do all of that well, you need a modern data stack. That’s not some abstract tech-focused notion: it’s a toolkit for enabling fast, reliable, data-driven decisions at scale.
In other words: a modern data stack is mission critical.
Here are the top tools for a modern data stack in 2025.
TL;DR: Best Modern Data Stack Tools in 2025
- ELT: Extract, Fivetran, Airbyte
- Transformation: dbt, Dataform
- Warehouse: Snowflake, BigQuery
- Orchestration: Airflow, Prefect
- Observability: Monte Carlo, Soda
- BI: Power BI, Tableau, Looker
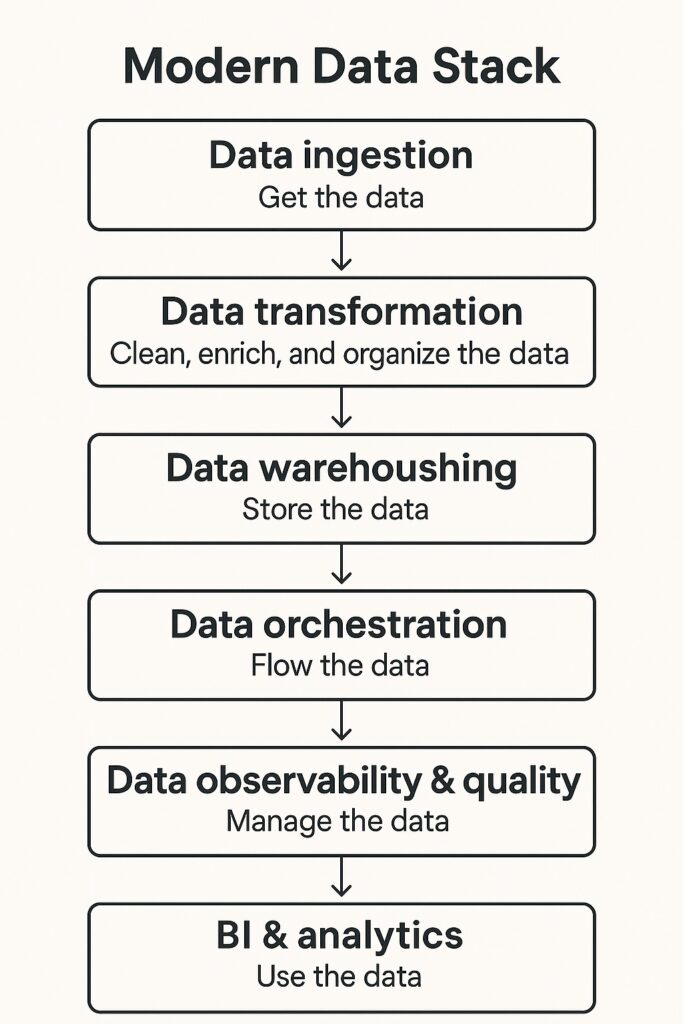
Modern data stack: 6 tiers of solutions
If the modern data stack is a cake, here are the layers:
- Data ingestion
Get the data - Data transformation
Clean, enrich, and organize the data - Data warehousing
Store the data - Data orchestration
Flow the data - Data observability & quality
Manage the data - BI & analytics
Use the data
It’s a complex stack. Not every company needs a full and complete modern data stack. But for most mid to large companies, you’re gonna need big chunks of it and probably all of it.
What that means is you’ll be choosing a solution for each slice of the pizza, each layer of the stack.
And what you choose is likely going to be 1 of the following.
Data ingestion: the first rung on the modern data stack
You have to get the data before you can use it. ELT data ingestion tools are how you do exactly that.
You’ll probably be picking 1 of these (and yeah, we’re listing our own ELT platform first):
- Extract
Newest, most usable, efficient, and cost-effective - Fivetran
Big, powerful, expensive - Airbyte
Open source, flexible, hard work to use/integrate - Matillion
Ingests and transforms, harder to scale - Hevo Data
Fewer connectors - Rivery
Fewer connectors
ELT brings raw data from all the places you manufacture or offgas into a central repository, either a data warehouse or data lake. What you need is a super-efficient tool that is fault-tolerant and easy to use.
(We suggest Extract fits that bill.)
Next step: Data transformation
Now you have the data. Great.
But … it’s not always exactly in the format/shape/size/color you want. Or, more specifically, in the schema and with the precise rows and columns that your downstream data-consuming applications need.
What to do?
Transform it.
Most likely with 1 or more of these tools …
- dbt
The default choice: powerful, scalable, easy to use, works everywhere - Dataform (BigQuery)
Popular for Google Cloud users, scalable - Coalesce
Integrated with and optimized for Snowflake
We used to do data transformation in-transit in tools like ETL. Now, in the modern data stack, we do it in the data warehouse, where there’s more power and more room, after getting the data with ELT tools.
Thank you, cloud data warehouses, for doing the heavy lifting.
Modern data stack tier 3: Data warehousing
Hello backbone of the modern data stack: data warehousing. After all, you got the data. You transformed it. Now you need to keep it somewhere better than under your bed or the cracks in the sofas.
Where?
Somewhere in 1 of these tools:
- Snowflake
Perhaps the gold standard, rich ecosystem - Google BigQuery
Decouples storage and compute, auto scales, easy to use, pay as you go - Amazon Redshift
Auto-scales, integrated with AWS, can be cheaper than Snowflake, may need more maintenance - Databricks Lakehouse
Data lake with data warehouse structure (see below), flexible, can be more complex
Modern cloud data warehouses are scalable, cost-effective, and highly performant systems. They’re a key component of the modern data stack. Choosing between them is tough, but often based on other tools and platforms you use, and cost savings you can extract.
Note: data lakes vs data warehouses
The primary difference between a data warehouse and a data lake is that a warehouse typically holds structured data, while a lake often holds unstructured data. Depending on your needs and use cases, a data lake might make sense in addition to or even in place of a data warehouse.
Data orchestration: tier 4 in the modern data stack
We got it, we changed it, we stored it. Awesome: now let’s put it to work. Data orchestration tools schedule and coordinate the flow of data for an enterprise.
How?
With 1 or more of these tools, most likely:
- Apache Airflow
Old faithful, still chugging. Scalable, integrated, steeper learning curve - Prefect
Modern, Python-centric, easy to use - Dagster
Newer, handles hybrid workflows, modular, developer-friendly - Google Cloud Workflows
Works great in the Google world - Azure Data Factory pipelines
Works great in the Microsoft world
Pretty much all of these can manage large-scale workflows. Choosing 1 generally comes down to flexibility vs. ease and what your team knows and likes.
Data observability & monitoring
Some of these functions might be embedded in your platforms or other tools, but as modern data stacks become critical infrastructure, data observability tools help you ensure reliability, quality, and performance.
Top tools here include:
- Monte Carlo
Default leader and pioneer, pricy - Great Expectations
Open source, set up and use can be challenging - Bigeye
Custom metrics, built for scale, requires significant configuration - Soda
Open source, developer-centric - Metaplane
Lightweight tool with quick set-up, easy to use
Data observability tools are looking for anomalies like sudden drops, spikes, or schema changes. They also track data dependencies, and alert you when they find issues in data quality or flow.
Adjacent tools that come out of the DevOps world include names like Datadog, Splunk, and Dynatrace. They are expanding into data pipeline monitoring, but tend to focus on infrastructure metrics or logs rather than data content.
The cherry on top of the modern data stack: Business intelligence and analytics
This is a critical part of the modern data stack: now you’re actually using the data to make business decisions.
BI and analytics tools enable end-users and analysts to create reports, dashboards, and interactive analyses using the data you’ve so painstakingly collected, changed, stored, and moved around.
These tools include:
- Microsoft Power BI
Big, robust, scalable, relatively affordable - Tableau
Rich visuals, easy to use, can be pricy - Google Looker
Model-driven approach for standardization, scalable - ThoughtSpot
Modern search interface, very accessible to newbies, scalable - Qlik Sense
Still a powerful tool - Domo
Deploys quickly - Apache Superset
Open source
Modern data stack comparison: best tools by layer in 2025
| Layer | Tool | Strengths | Considerations |
|---|---|---|---|
| Data Ingestion (ELT) | Extract | Fast, efficient, cost-effective, easy to use, great for startups | Newer, smaller ecosystem |
| Fivetran | Enterprise-grade, robust, highly integrated | Expensive | |
| Airbyte | Open source, flexible, customizable | Requires setup, technical skills | |
| Matillion | Ingest + transform, visual UI | Harder to scale | |
| Hevo Data | Easy setup, solid support | Fewer connectors | |
| Rivery | All-in-one platform, no-code workflows | Limited breadth | |
| Data Transformation | dbt | Powerful, scalable, industry standard | Requires dbt skills |
| Dataform | Great for BigQuery users | Google Cloud-focused | |
| Coalesce | Snowflake-native, visual UI | Still growing ecosystem | |
| Data Warehousing | Snowflake | Industry leader, flexible, large ecosystem | Can get expensive |
| BigQuery | Pay-as-you-go, serverless, auto-scaling | Tied to Google Cloud | |
| Amazon Redshift | Tight AWS integration, good performance | More maintenance needed | |
| Databricks Lakehouse | Combines data lake + warehouse, flexible for AI/ML | Steeper learning curve | |
| Orchestration | Apache Airflow | Scalable, widely used | Steep learning curve |
| Prefect | Modern, Pythonic, easy to use | Still evolving | |
| Dagster | Hybrid workflows, modular | Less mature than Airflow | |
| GCP Workflows | Best for GCP users | Tied to Google Cloud | |
| Azure Data Factory | Microsoft-friendly | Limited cross-platform support | |
| Data Observability | Monte Carlo | Market leader, powerful detection | Expensive |
| Great Expectations | Open source, customizable | Harder to set up | |
| Bigeye | Custom metrics, built for scale | Requires configuration | |
| Soda | Open source, dev-friendly | Best for engineers | |
| Metaplane | Lightweight, fast setup, easy UI | Fewer advanced features | |
| BI & Analytics | Power BI | Affordable, Microsoft ecosystem | Less flexible for non-MS users |
| Tableau | Great visuals, powerful dashboards | Can be pricey | |
| Looker | Model-based, scalable | Requires LookML learning | |
| ThoughtSpot | Search-driven, very accessible | Newer to some teams | |
| Qlik Sense | Solid features, long-time player | UI can feel dated | |
| Domo | Quick deployment, all-in-one | Pricing can be high | |
| Apache Superset | Open source | Requires setup and maintenance |
Here’s the modern data stack layer cake
Building a modern data stack in 2025 means selecting best-in-class, cloud-native tools for each stage of the data lifecycle and ensuring they work in harmony.
Key factors for deciding which layers of the cake you’ll pick, and which ingredients you’ll use for each layer, requires looking at each platform’s strengths and weaknesses and then aligning them to your org’s needs.
They typically include
- Scalability
- Integration
- Cost
- Ease of deployment
- Ease of use
It’s important to note that the modern data stack is not one-size-fits-all. The “best” tool for someone else may not be the best tool for you. And, each layer in the cake is adding functionality for other layers, so you may not need to have a 1:1 relationship between jobs and tools.
That makes life easier, of course.
One thing we’ll respectfully submit: for data ingestion and ETL, don’t sleep on Extract. We’re new, we’re young, but we’re super fast, super efficient, and super cost effective.